Database
Based on the needs of an application we can choose to make use of different data models for storing the data.
-
Document databases
-
Relational databases
-
Graph databases
It’s hard to say which approach is better, unless we go into the details of the type of application we are going to be building. For our specific purposes, being that we are going to deal with personal finances. But not in a highly interconnected way in which we have tons of many-to-many relationships and the need to perform tons of joins into them for different cross-user querying. We will follow a document database approach.
Specifically, we will leverage Redis OM. Which is a specific library
(that is built on top of StackExchange.Redis) that leverages Redis' native JSON
document data type to store data to then connect that to an application by becoming a
translation layer at the level of an Object Mapper.
The document’s structure will try to leverage locality as much as possible, having all the bookkeeper’s information under the same document, allowing for us to have access to data related to him and his finances without the need for client-side joining. And it’s also due to the start-upy nature of the whole project, in which new ideas might start coming later, and/or we require for a fast development experience without too many hurdles that schema-ful databases might impose. (But it’s worth noting that the integration with EF Core (in .NET specifically), allows for this overhead to be greatly simplified, since the concept of automated migrations auto-generated from the object’s we write at the application level is a god-send when used correctly).
Conventions
And since a clear line needs to be drawn, these are the conventions we will use for the different aspects of our database:
-
Database names ⇒
snake_case(Documents, fields, constraints) (always in plural) -
Primary IDs ⇒
idordocument_id -
Document references ⇒
document_id -
Indexes/constraints ⇒
idx_,fk_,chk_
And due to the Document based nature of how we will store our data in Redis, the diagram we chose to represent it will be of a Class Diagram, however with a tree-like structure. It’s imperative to leave clear that we will store inside of a parent object in which all the other children will hold themselves other levels of data.
And it’s also important to state clearly that Redis is a key-value store. It’s not relational in nature, and it doesn’t enforce schemas like SQL databases. It’s through the usage of its own convention in the form of key paths that we will be able to store our documents with a clear logical order in mind. It will be through this usage that we will also adhere to the modular monolith architecture pattern, specifically on the concern of isolating data between modules.
Another important convention we will always aim at adhering to is to never physically
delete records. (Unless a compelling argument arises for doing so). We should always
have a deleted field with a true representing the record is logically deleted (or not).
|
The conventions on field names and document names will apply mostly for diagram and
theoretical purposes (this is an extra overhead, and we will assume that). However,
on the physical system, we will be using Microsoft’s convention since it will map directly
from class and property field names (Pascal Case). This is mostly due to the fact that
|
Key Paths
We will hold a structure such as:
-
auth
-
user (E.g.,
auth:user:1)
-
-
finances (E.g.,
finances:*)-
TBD
-
-
intelligence (E.g.,
intelligence:*)-
TBD
-
-
users (E.g.,
users:*)-
TBD
-
-
projection (E.g.,
projection:*)-
TBD
-
And it’s each entry that will correspond to a numeral ID that we will have our documents saved to. As you can see the parent key path will be of the respective module.
Documents diagram
We will document each module’s data document structure in isolation (following the idea of the Modular Monolith approach), but also for simplicity and readability’s sake.
Authentication Module
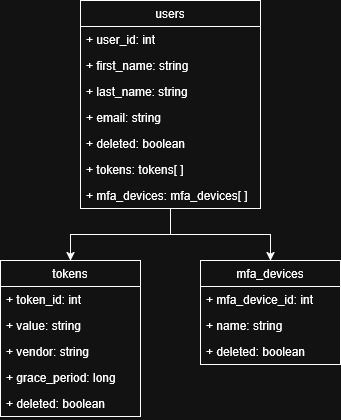
Figure 1. Authentication module’s data model
-
usersis the heart of this module (aggregate root in DDD), it will save data that Google’s API will provide on the initial handshake plus storing in a nested document array the different tokens that might be created across the usage of the system. BIG NOTE: Each new record on thetokenscollection should have itsvaluefield blanked out the moment it’s marked asdeletedfor security purposes (plus having that same token revoked on the Google side).
Also attached to the user we will have a list of different MFA devices in case the user configures one.
Extra Note: One of the most important pieces of information on this module will be
the email from a user, plus a value from a token attached to the user. It’s due
to this very fact that those two values must be encrypted
and only decrypted at run-time for specific usage of their underlying values.
One key part of this whole module’s data model is the fact that we are using int
as the ID for each document. This is on purpose to have an easier time tying that
back to the Redis keypaths, being that if we were to use GUIDs of any nature, the
readability and ease of search for records would be vastly more challenging. (For other
use cases, a GUID would be more suited, specially if we know that an int would reach
its maximum value over time on the system).